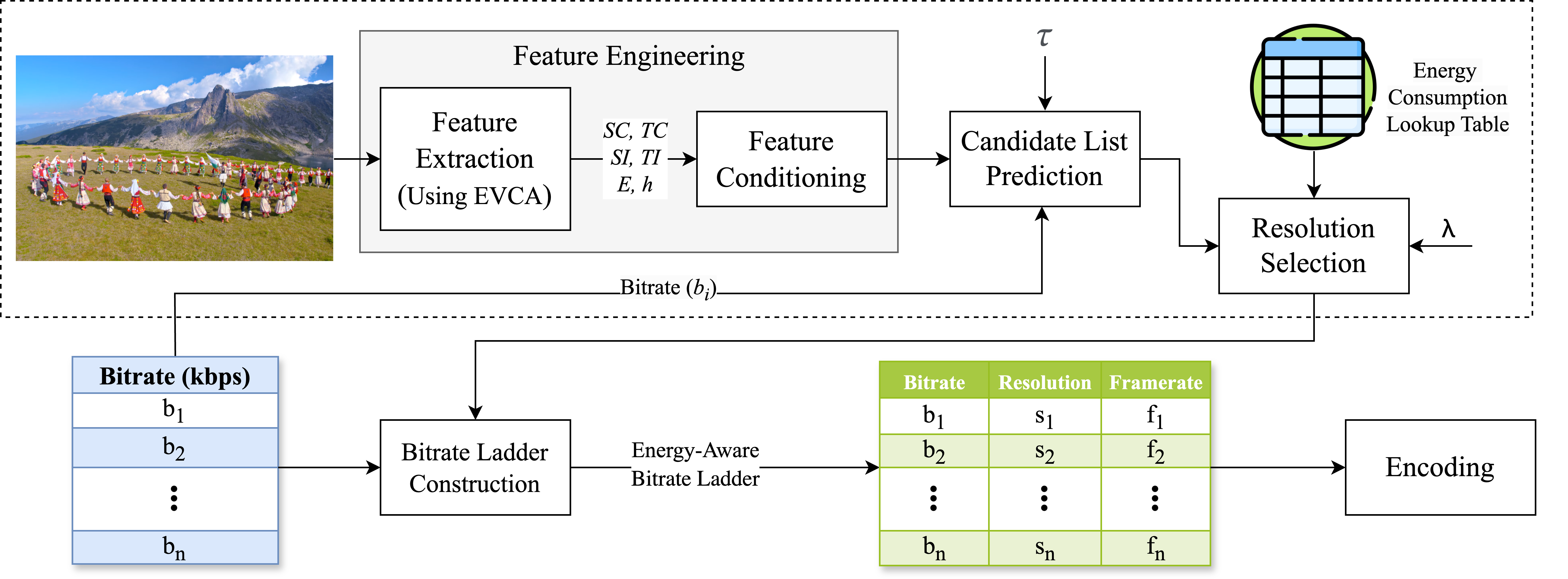
Convex Hull Prediction Methods for Bitrate Ladder Construction: Design, Evaluation, and Comparison
ACM Transactions on Multimedia Computing Communications and Applications (ACM TOMM)
[PDF]
Ahmed Telili (INSA, Rennes, France), Wassim Hamidouce (INSA, Rennes, France), Hadi Amirpour (Alpen-Adria-Universität Klagenfurt), Sid Ahmed Fezza (INPTIC, Algeira), Christian Timmerer (Alpen-Adria-Universität Klagenfurt), and Luce Morin (INSA, Rennes, France)
Abstract:
HTTP adaptive streaming (HAS ) has emerged as a prevalent approach for over-the-top (OTT ) video streaming services due to its ability to deliver a seamless user experience. A fundamental component of HAS is the bitrate ladder, which comprises a set of encoding parameters (e.g., bitrate-resolution pairs) used to encode the source video into multiple representations. This adaptive bitrate ladder enables the client’s video player to dynamically adjust the quality of the video stream in real-time based on fluctuations in network conditions, ensuring uninterrupted playback by selecting the most suitable representation for the available bandwidth. The most straightforward approach involves using a fixed bitrate ladder for all videos, consisting of pre-determined bitrate-resolution pairs known as one-size-fits-all. Conversely, the most reliable technique relies on intensively encoding all resolutions over a wide range of bitrates to build the convex hull, thereby optimizing the bitrate ladder by selecting the representations from the convex hull for each specific video. Several techniques have been proposed to predict content-based ladders without performing a costly, exhaustive search encoding. This paper provides a comprehensive review of various convex hull prediction methods, including both conventional and learning-based approaches. Furthermore, we conduct a benchmark study of several handcrafted- and deep learning ( DL )-based approaches for predicting content-optimized convex hulls across multiple codec settings. The considered methods are evaluated on our proposed large-scale dataset, which includes 300 UHD video shots encoded with software and hardware encoders using three state-of-the-art video standards, including AVC /H.264, HEVC /H.265, and VVC /H.266, at various bitrate points. Our analysis provides valuable insights and establishes baseline performance for future research in this field.
Dataset URL: https://nasext-vaader.insa-rennes.fr/ietr-vaader/datasets/br_ladder