VCA-FFMPEG: A FFmpeg Filter for Video Complexity Analysis
34th ACM International Conference on Multimedia 2026 (ACM MM 2026)
10–14 November 2026
Rio de Janeiro, Brazil
[PDF]
Hadi Amirpour (AAU, Austria), Mykyta Skipenko (AAU, Austria), and Christian Timmerer (AAU, Austria)
Abstract:
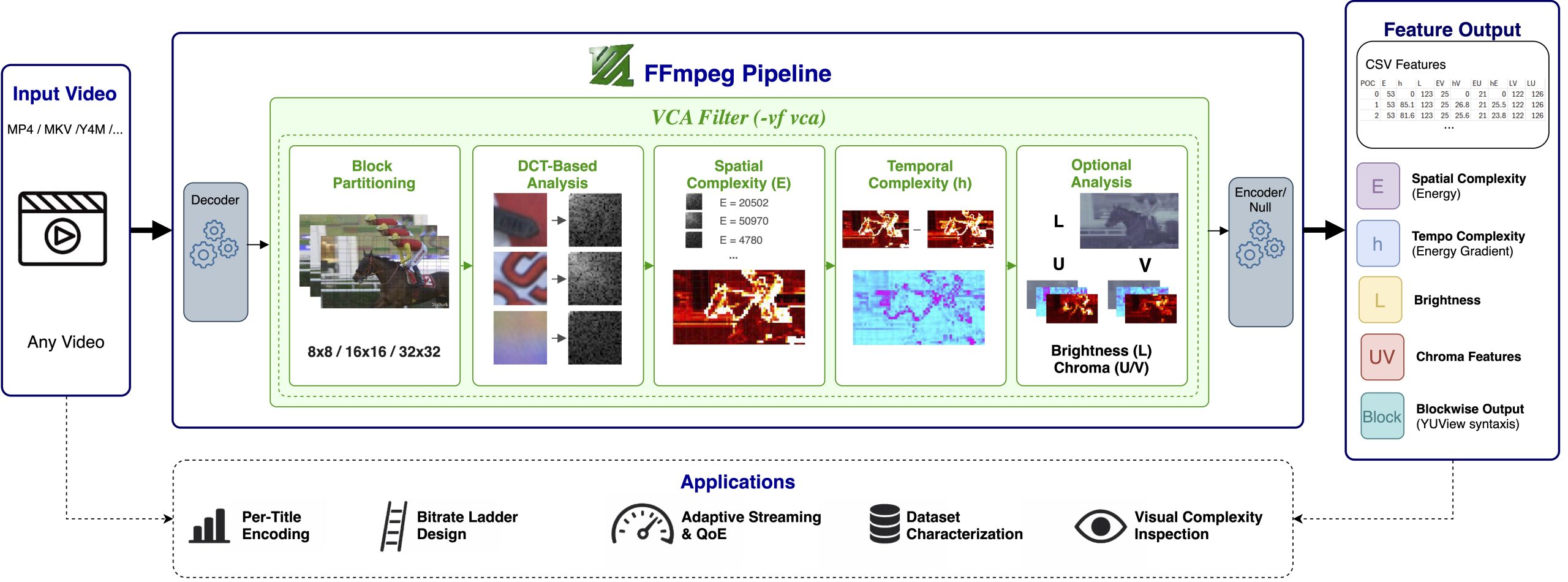
VCA is a widely used open-source framework for estimating spatial and temporal video complexity features for applications such as per-title encoding, bitrate ladder generation, and content-adaptive streaming. However, the original VCA workflow requires videos to be preprocessed into raw formats such as YUV or Y4M before analysis, introducing additional decoding, conversion, storage, and pipeline overhead. Moreover, the standalone implementation has limited portability across platforms, devices, and heterogeneous multimedia processing systems.
In this paper, we present VCA-FFmpeg, an open-source integration of VCA as a native filter inside the FFmpeg multimedia framework. By embedding VCA directly into FFmpeg’s filtering pipeline, the proposed system removes the need for external preprocessing and intermediate format conversion, enabling complexity analysis on virtually any video format supported by FFmpeg. The integration allows users to extract spatial, temporal, brightness, and chroma descriptors during standard decoding, transcoding, or filtering operations using a simple command-line interface.
VCA-FFmpeg supports configurable block-based analysis, multi-threaded execution, optional low-pass DCT acceleration, SIMD optimizations, and YUView-compatible block-level visualization. Since FFmpeg is broadly supported across operating systems and hardware platforms, the proposed framework improves portability, usability, and reproducibility compared to standalone VCA. In our runtime evaluation, VCA-FFmpeg processed MP4 input at 462.7 fps, compared with 194.5 fps for the standalone workflow that first converts MP4 to Y4M and then applies VCA. By leveraging FFmpeg’s multimedia ecosystem, VCA-FFmpeg provides an efficient and scalable solution for in-pipeline video complexity feature extraction in multimedia systems, adaptive streaming, and video coding research.