EPS: Efficient Patch Sampling for Video Overfitting
in Deep Super-Resolution Model Training
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
[PDF]
Yiying Wei (AAU, Austria), Hadi Amirpour (AAU, Austria), Jong Hwan Ko (SKKU, South Korea), and Christian Timmerer (AAU, Austria)
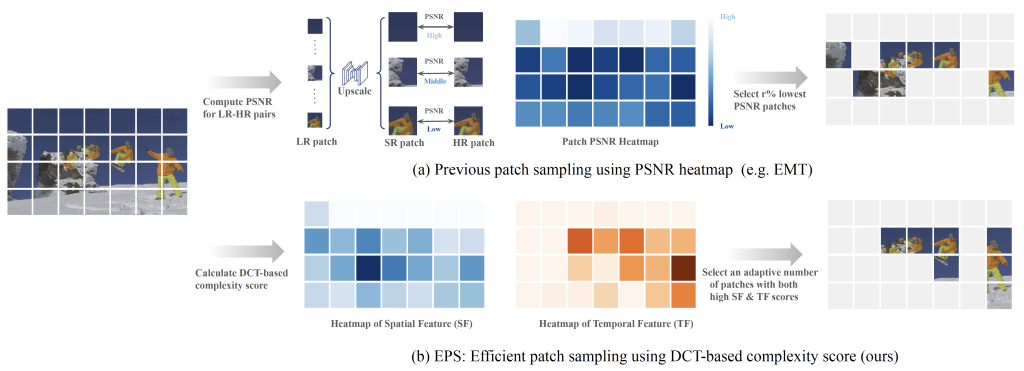
Abstract: Leveraging the overfitting property of deep neural networks (DNNs) is trending in video delivery systems to enhance video quality within bandwidth limits. Existing approaches transmit overfitted super-resolution (SR) model streams for low-resolution (LR) bitstreams, which are used to reconstruct high-resolution (HR) videos at the decoder. Although these approaches show promising results, the huge computational costs of training a large number of video frames limit their practical applications. To overcome this challenge, we propose an efficient patch sampling method named EPS for video SR network overfitting, which identifies the most valuable training patches from video frames.
To this end, we first present two low-complexity Discrete Cosine Transform (DCT)-based spatial-temporal features to measure the complexity score of each patch directly. By analyzing the histogram distribution of these features, we then categorize all possible patches into different clusters and select training patches from the cluster with the highest spatial-temporal information. The number of sampled patches is adaptive based on the video content, addressing the trade-off between training complexity and efficiency.
Our method reduces the number of training patches by 75.00% to 91.69%, depending on the resolution and number of clusters, while preserving high video quality and greatly improving training efficiency. Our method speeds up patch sampling by up to 82.1× compared to the state-of-the-art patch sampling technique (EMT).