Content-Adaptive Encoding Pass Selection for Efficient Video Streaming
International Workshop on Multimedia Signal Processing (MMSP)
September 22 – September 24, 2026
Istanbul, Türkiye
[PDF]
Mohammad Ghasempour (AAU, Austria), Hadi Amirpour (AAU, Austria), Christian Timmerer (AAU, Austria)
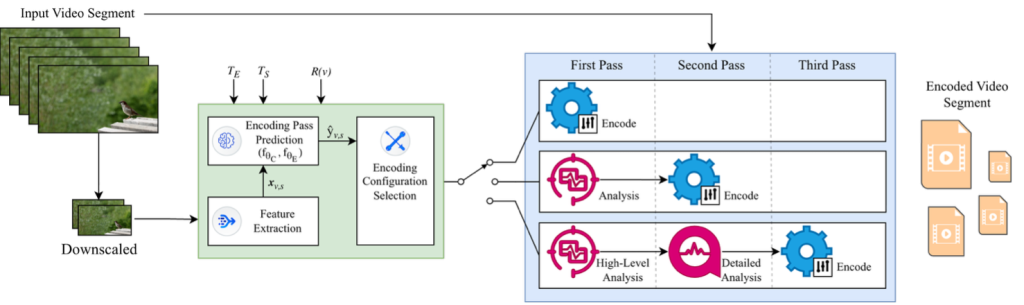
Abstract: As video streaming continues to grow in scale, improving the efficiency of video encoding has become increasingly important to balance visual quality and computational cost. Multi-pass encoding is widely adopted to enhance compression efficiency, improve rate control, and achieve more stable quality by leveraging additional analysis of video content prior to encoding. These benefits come with the cost of increased computational complexity. In this paper, we show that the benefits of multi-pass encoding vary substantially across video content and encoding configurations in adaptive video streaming. Motivated by this observation, we propose the Adaptive Encoding Pass Selection (AEPS), a lightweight content-adaptive framework that estimates the benefits of multi-pass prior to encoding and enables selective use of single-pass encoding to reduce encoding time. Experimental results demonstrate that the AEPS framework substantially reduces encoding time while maintaining compression performance and stability, achieving an average 25.3% reduction in encoding time with only a 2.23% increase in bitrate. We show that the preprocessing and decision-making overhead of AEPS is approximately 1155 times lower than the time required for multi-pass encoding in adaptive streaming.