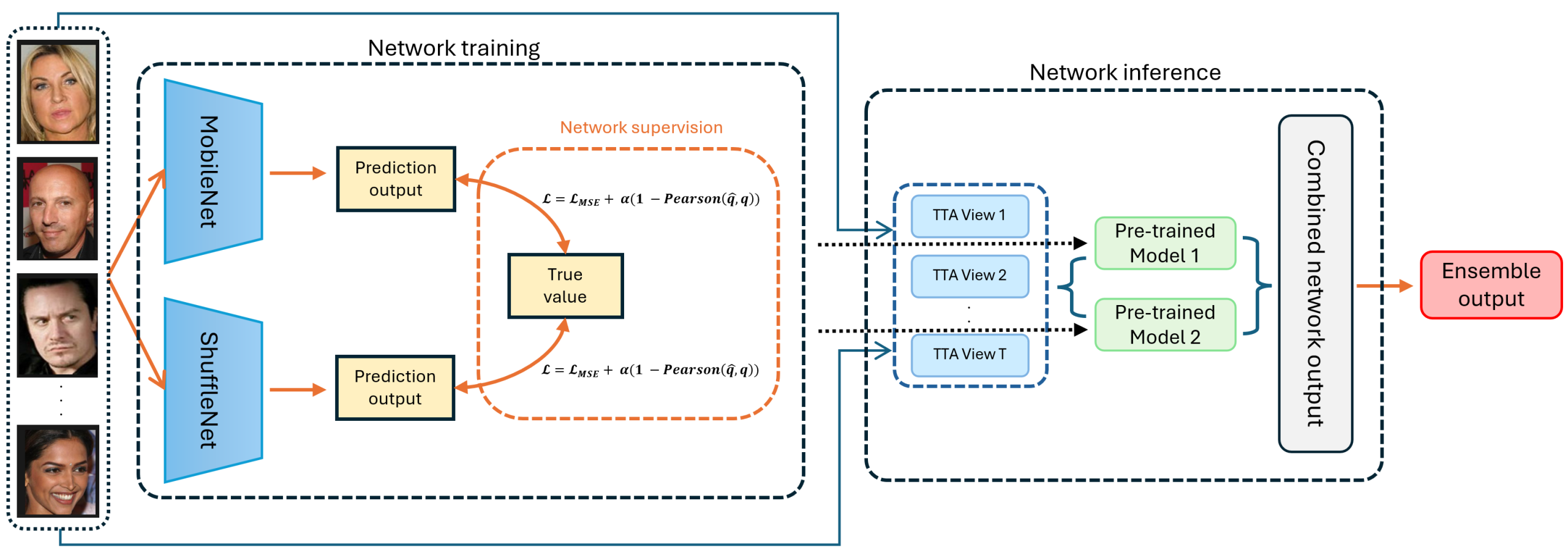
VQualA 2025 Challenge on Image Super-Resolution Generated Content Quality Assessment: Methods and Results
ICCV VQualA 2025
October 19 – October 23, 2025
Hawai’i, USA
[PDF]
Hadi Amirpour (AAU, Austria), et al.
Abstract: This paper presents the ISRGC-Q Challenge, built upon the Image Super-Resolution Generated Content Quality Assessment (ISRGen-QA) dataset, and organized as part of the Visual Quality Assessment (VQualA) Competition at the ICCV 2025 Workshops. Unlike existing Super-Resolution Image Quality Assessment (SR-IQA) datasets, ISRGen-QA places greater emphasis on SR images generated by the latest generative approaches, including Generative Adversarial Networks (GANs) and diffusion models. The primary goal of this challenge is to analyze the unique artifacts introduced by modern super-resolution techniques and to evaluate their perceptual quality effectively. A total of 108 participants registered for the challenge, with 4 teams submitting valid solutions and fact sheets for the final testing phase. These submissions demonstrated state-of-the-art (SOTA) performance on the ISRGen-QA dataset. The project is publicly available at: https://github.com/Lighting-YXLI/ISRGen-QA.