Perceptual JND Prediction for VMAF Using Content-Adaptive Dual-Path Attention
IEEE VCIP 2025
December 1 – December 4, 2025
Klagenfurt, Austria
[PDF]
MohammadAli Hamidi (University of Cagliari, Italy), Hadi Amirpour (AAU, Austria), Christian Timmerer (AAU, Austria), Luigi Atzori (University of Cagliari, Italy)
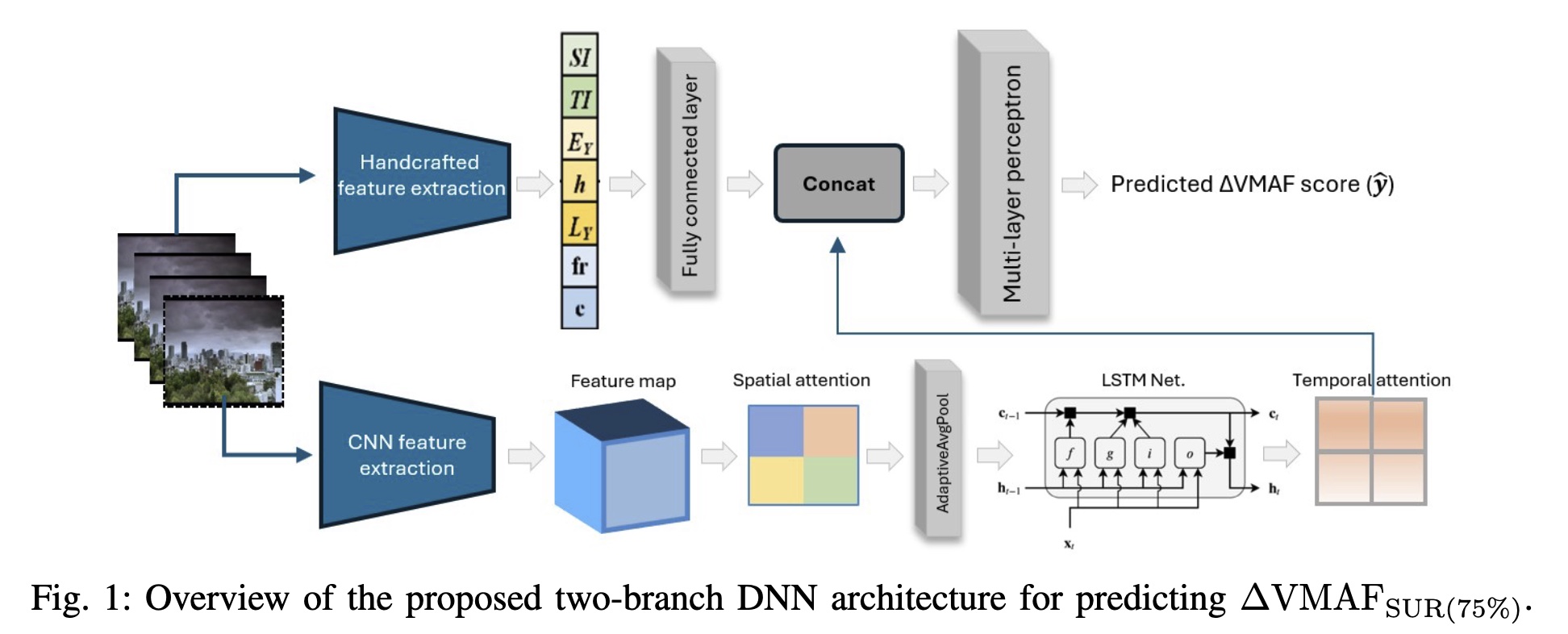
Abstract: Just Noticeable Difference (JND) thresholds, particularly for quality metrics such as Video Multimethod Assessment Fusion (VMAF), are critical in streaming, helping identify when quality changes become perceptible and reducing redundant bitrate representations. The Satisfied User Ratio (SUR) complements JND by quantifying the percentage of users who do not perceive a difference, offering practical guidance for perceptually optimized streaming. This paper proposes a novel two-branch deep neural network (DNN) for predicting the 75% SUR for VMAF, the encoding level where 75% of viewers cannot perceive degradation. The framework combines handcrafted features (e.g., spatial and temporal indicators such as SI, TI, etc. and deep learning-based (DL-based) representations extracted via a convolutional neural network (CNN) backbone. The DL-based branch employs a spatio-temporal attention mechanism and a Long Short-Term Memory (LSTM) to capture temporal dynamics, while the handcrafted branch encodes interpretable indicators through a fully connected layer. Both outputs are fused and passed through a lightweight Multilayer Perceptron (MLP) to predict 75% SUR. To improve robustness to noise and label uncertainty, the model is trained using the Smooth-L1 loss. Experiments on the VideoSet dataset show our method outperforms SOTA across all metrics, achieving a notably higher R² score (0.46 vs. 0.36), indicating improved prediction reliability and low computational complexity, making it suitable for real-time video streaming.