ELLMPEG: An Edge-based Agentic LLM Video Processing Tool
The 17th ACM Multimedia System Conference (MMSys’26)
Hong Kong SAR
4th – 8th April 2026
Zoha Azimi, Reza Farahani, Radu Prodan, Christian Timmerer
Abstract: Large language models (LLMs), the foundation of generative AI systems like ChatGPT, are transforming many fields and applications, including multimedia, enabling more advanced content generation, analysis, and interaction. However, cloud-based LLM deployments face three key limitations: high computational and energy demands, privacy and reliability risks from remote processing, and recurring API costs. Recent advances in agentic AI, especially in structured reasoning and tool use, offer a better way to exploit open and locally deployed tools and LLM models. This paper presents ELLMPEG, an
edge-enabled agentic LLM framework for the automated generation of video-processing commands. ELLMPEG integrates tool-aware Retrieval-Augmented Generation (RAG) with iterative self-reflection to produce and locally verify executable FFmpeg and VVenC com-
mands directly at the edge, eliminating reliance on external cloud APIs. To evaluate ELLMPEG, we collect a dedicated prompt dataset comprising 480 diverse queries covering different categories of FFmpeg and the Versatile Video Codec (VVC) encoder (VVenC) com-
mands. We validate command generation accuracy and evaluate four open-source LLMs based on command validity, tokens generated per second, inference time, and energy efficiency. We also execute the generated commands to assess their runtime correctness and practical applicability. Experimental results show that Qwen2.5, when augmented with the ELLMPEG framework, achieves an average command-generation accuracy of 78 % with zero recurring API cost, outperforming all other open-source models across both the FFmpeg and VVenC datasets.
Posted inATHENA|Comments Off on ELLMPEG: An Edge-based Agentic LLM Video Processing Tool
Residual U-Network: 3D Point Cloud-Based Automotive Pressure Field Prediction Model
18th International Congress on Image and Signal Processing, BioMedical Engineering, and Informatics (CISP-BMEI 2025)
October 25 – 27, 2025
Qingdao, China
http://www.cisp-bmei.cn/
Hezhi Li, Hongyou Chen, Lingfeng Qu, Baodan Tian, Yong Fan, Hadi Amirpour, and Christian Timmerer
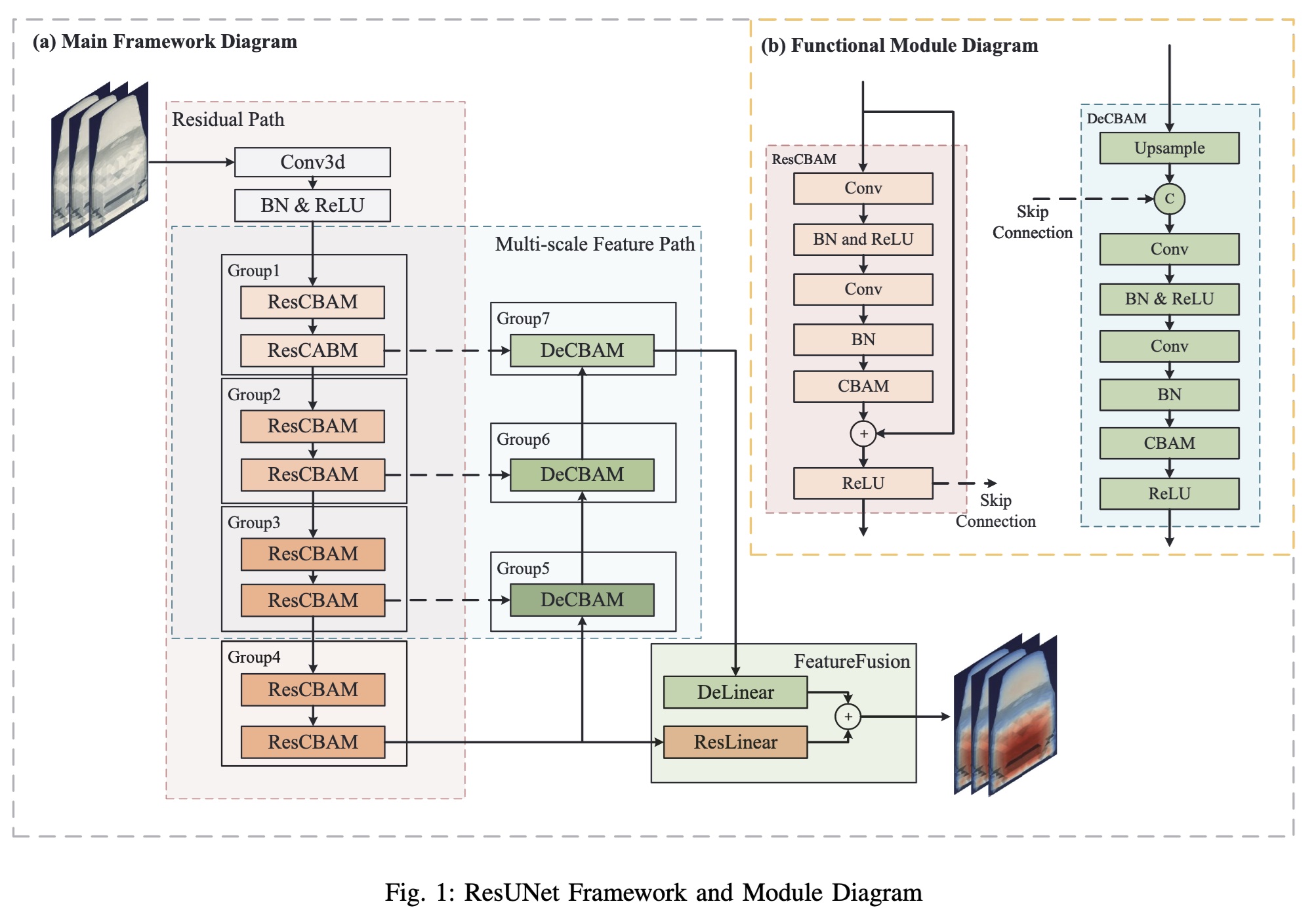
Abstract: Automotive surface pressure field prediction is important for design optimization and performance evaluation of vehicle aerodynamics, fuel efficiency, and automotive safety. Although traditional computational fluid dynamics methods are accurate, they incur high computational costs and are time-consuming. Most existing deep learning methods show limitations in learning pressure variation features near complex geometric shapes of automotive exteriors. To address these issues, this paper proposes a deep learning method based on a hybrid architecture combining Residual Network (ResNet) and U-Network (UNet). The method processes 3D point cloud representations of automotive geometries by converting them into structured grid formats with signed distance function values for efficient neural network processing. The method improves the model’s predictive capability for complex geometric regions by integrating the Convolutional Block Attention Module (CBAM) attention mechanism. In the model, the Residual Convolutional Block Attention Module (ResCBAM) combines residual connections with channel and spatial attention mechanisms to improve perception of key pressure field features. The Decoder Convolutional Block Attention Module (DeCBAM) fuses multi-scale feature information in the decoder pathway, recovering neural network feature details. The feature fusion module integrates global flow field distribution features extracted by the encoder with local geometric detail features reconstructed by the decoder. Additionally, an automated hyperparameter optimization strategy is employed to improve the model’s prediction accuracy and generalization capability. To validate model performance, experiments are conducted on three automotive surface pressure datasets. Experimental results demonstrate that the proposed model achieves better prediction accuracy and generalization capability.
Posted inATHENA|Comments Off on Residual U-Network: 3D Point Cloud-Based Automotive Pressure Field Prediction Model
Generative Visual Coding (GVC) is an emerging paradigm that explores how generative models and structured visual representations can redefine visual communication. By integrating generative capabilities into the coding process, GVC enables new forms of representation, transmission, and reconstruction that enhance perceptual and semantic fidelity while improving communication efficiency. Beyond human-centric reconstruction, GVC supports machine- and task-oriented communication, where compact and semantically meaningful representations benefit downstream analysis and decision-making.
The paradigm also motivates theoretical study on how generative priors interact with information constraints, optimization objectives, and emerging concepts in semantic communication. As generative processes gain prominence, principled evaluation becomes increasingly essential, encouraging advances in quality assessment, distortion modeling, and the development of benchmark datasets for generative and hybrid codec systems. Efficiency remains central to deployment, underscoring the importance of model design, complexity optimization, and computational scalability.
GVC further extends to immersive and spatial communication, including three-dimensional and scene-level content. In these settings, generative models can infer geometry, semantics, and contextual relationships, enabling new modes of multi-view and interactive media delivery. Overall, GVC offers a unified framework that integrates generative modeling, visual coding, and intelligent communication, laying the groundwork for next-generation visual communication systems.
Scope / Topics
Generative foundation models, methodologies, frameworks, and analytical perspectives for visual coding and task-oriented communication
Theoretical modeling and rate–distortion perspectives for generative and semantic visual communication
Evaluation frameworks, quality assessment, and benchmark datasets for generative coding systems
Complexity optimization for generative visual communication
Generative coding use cases (e.g., Generative Face Video Coding)
Generative visual communication for immersive, three-dimensional, and spatially aware media
Paper Format: up to 5 pages + 1 page of only references (see Author Kit)
Topic Selection: When submitting, select Special Session ‘Generative Visual Coding: Emerging Paradigms for Future Communication’ as well as up to two additional regular topics (Step 5)
Important Dates
Special Session Submission Opens: January 7, 2026
Paper Submission Deadline: February 4, 2026 (Extended)
Notification of Acceptance: April 22, 2026
Camera-Ready Paper Due: May 13, 2026
Organizers
Jianhui Chang, China Telecom Cloud Computing Research Institute
Hadi Amirpour, University of Klagenfurt
Giuseppe Valenzise, Université Paris-Saclay
Posted inATHENA|Comments Off on ICIP’26 Special Session: Generative Visual Coding: Emerging Paradigms for Future Communication
Immersive systems such as Virtual and Extended Reality are becoming widespread thanks to the wide diffusion of relatively low-cost headsets and the increased immersivity and sense of presence they provide with respect to their 2D counterparts. However, the novelty of the involved technologies as well as the variety of available media types, together with the high number of applications, entail endless challenges for the research community. One key feature of immersive systems is that they inherently place users at the center of the experience, allowing them to actively explore, manipulate, and interact with content. As a result, immersive systems introduce new perceptual, behavioral, and interaction aspects that require dedicated investigation. This special session focuses on the role of visual information processing in enabling human-centered immersive experiences, providing complementary insights into how visual information plays a critical role in enhancing effectiveness, comfort, usability, and perceptual quality in next-generation immersive applications.
Topics of interest
Visual attention mechanisms
Perceptual modelling
Emerging media formats (stereoscopic and omnidirectional imagery, light fields, point clouds, meshes, and Gaussian splats)
Topicselection: when submitting your paper, you will be able to find the accepted special sessions as part of the list of topics (Step 5). Please make sure to select the Special Session ‘Visual information processing for human-centered immersive experiences’ as well as up to two additional regular topics, to assist in the review process and for program-building purposes.
Format: up to 5 pages + 1 page for references only (refer to the Author Kit)
Vignesh Menon (Alpen-Adria-Universität Klagenfurt, Austria), Hadi Amirpour (Alpen-Adria-Universität Klagenfurt, Austria), and Christian Timmerer (Alpen-Adria-Universität Klagenfurt, Austria)
Abstract: Techniques for predicting video encoding complexity are described herein. A method for predicting video encoding complexity includes performing video complexity feature extraction on a video segment to extract low-complexity frame-based features, predicting video encoding complexity for the video segment using the low-complexity frame-based features, and outputting a predicted encoding bitrate and a predicted encoding time. An embodiment may include implementing a hybrid model using a CNN, wherein a latent vector from a frame of the video segment is extracted and also may be used to predict video encoding complexity. The predicted encoding bitrates and encoding times may be provided to encoding infrastructure for use in optimizing a schedule of encodings.
Posted inATHENA|Comments Off on Patent Approval for “Video encoding complexity predictor”
Congratulations to Dr. Daniele Lorenzi for successfully defending his dissertation on “QoE- and Energy-aware Content Consumption for HTTP Adaptive Streaming” at Universität Klagenfurt in the context of the Christian Doppler Laboratory ATHENA.
Abstract
HTTP Adaptive Streaming (HAS) has become the dominant paradigm for video delivery over the Internet, enabling scalable and flexible content consumption across heterogeneous networks and devices. The continuous growth of video traffic, coupled with the increasing complexity of multimedia content and the proliferation of resource-constrained devices, poses significant challenges for streaming systems. In particular, service providers and researchers must jointly address Quality of Experience (QoE), energy consumption, and emerging protocol and content technologies to meet user expectations while ensuring sustainable operation.
This dissertation investigates QoE- and energy-aware content consumption in HAS, with a primary focus on client-side adaptation mechanisms. Through a systematic analysis of existing approaches, the thesis identifies key limitations in current Adaptive Bitrate (ABR) algorithms, which often prioritize bitrate maximization without sufficiently considering perceptual quality, energy efficiency, codec diversity, or new networking capabilities. To address these challenges, the dissertation proposes a set of novel methodologies, algorithms, and datasets that jointly optimize QoE and energy consumption under realistic network and device constraints.
The first contribution explores the exploitation of emerging transport protocols, specifically HTTP/3 and QUIC, to enhance QoE in HAS. The proposed DoFP+ approach leverages advanced protocol features such as stream multiplexing, prioritization, and termination to upgrade previously downloaded low-quality segments during playback. Extensive experimental evaluations demonstrate significant QoE improvements, reduced stall events, and more efficient bandwidth utilization compared to state-of-the-art approaches.
As a second contribution, the dissertation addresses the limitations of single-codec streaming by introducing MEDUSA, a dynamic multi-codec ABR approach. MEDUSA enables per-segment codec selection based on content-aware perceptual quality and segment size information, allowing the system to adapt to varying content complexity over time. Results show that dynamic codec switching can substantially improve perceptual quality while reducing transmitted data volume, thereby benefiting both end users and streaming providers.
The third contribution focuses on sustainable video streaming through energy-aware adaptation. The thesis introduces E-WISH, an energy-aware ABR algorithm that incorporates an explicit energy consumption model into the quality selection process, reducing playback stalls and lowering power usage without compromising QoE. To support systematic energy evaluations, the dissertation further presents COCONUT, a comprehensive dataset of fine-grained energy measurements collected from multiple client devices. This dataset enables in-depth analysis of the impact of video, device, and network parameters on energy consumption in HAS.
Finally, the dissertation investigates neural-enhanced streaming (NES), where client-side machine learning techniques are used to improve visual quality at the cost of additional computational overhead. To balance QoE gains and power consumption in heterogeneous client environments, the thesis proposes Receptive, a coordinated system that jointly optimizes ABR decisions and neural enhancement strategies across multiple users. Experimental results demonstrate that Receptive achieves substantial QoE improvements while significantly reducing energy consumption on NES-capable devices.
Overall, this dissertation advances the state of the art in HTTP Adaptive Streaming by introducing protocol-aware, content-aware, and energy-aware adaptation mechanisms, complemented by realistic datasets and comprehensive evaluations. The presented contributions provide a solid foundation for future research and practical deployments aiming to deliver high-quality, energy-efficient, and sustainable video streaming services.
VCIP 2025 in Klagenfurt: Advancing Sustainable and Trustworthy Visual Communications in the Age of AI
From December 1–4, 2025, the Department of Information Technology (ITEC) at the University of Klagenfurt (Austria) hosted the International Conference on Visual Communications and Image Processing (VCIP 2025), welcoming an international community of researchers, practitioners, and industry experts to discuss the future of visual communication and image processing. Under the theme “Sustainable and Trustworthy Visual Communications in the Age of AI,” the conference addressed some of the most pressing challenges and opportunities facing the field today.
A forum for cutting-edge research and dialogue
VCIP 2025 continued the long-standing tradition of the conference as a premier venue for both foundational and applied research. Over four days, the program offered a diverse range of tutorials, overview talks, keynotes, oral and poster sessions, and interactive formats. Discussions ranged from adaptive and low-latency streaming, source coding, and compressed-domain processing to volumetric media, computational vision, quality assessment, and AI-driven restoration and enhancement techniques.
Inspiring keynotes on trust, sustainability, and clarity
A particular highlight of VCIP 2025 were the three keynote talks, which set the tone for the conference by connecting technical innovation with broader societal concerns. The speakers addressed trustworthy multimedia communication in the era of AI-generated content, the environmental impact and sustainability of visual technologies, and the role of visual analytics in making complex data understandable across time and space. Together, the keynotes sparked lively discussions that extended well beyond the conference halls.
Tutorials, overview talks, and emerging topics
Four half-day tutorials provided in-depth insights into current and emerging technologies, including generative face video coding for ultra-low bitrate communication, JPEG AI standardization and implementation, the convergence of low-level image processing and generative AI, and the past, present, and future of volumetric video. Complementing these, overview talks offered broader perspectives on emotion and quality estimation, AI-enabled video streaming efficiency, 3D scene capture and compression, and the use of large vision–language models for visual quality assessment.
Supporting early-career researchers and innovation
VCIP 2025 placed strong emphasis on nurturing the next generation of researchers. The doctoral symposium and the VSPC Rising Star session provided a platform for early-career scientists to present their work and engage with senior experts. Demo, open-source, and dataset sessions further highlighted the practical impact of research, showcasing tools, prototypes, and resources that bridge theory and application.
Exchange beyond the technical program
In addition to the scientific sessions, the conference offered a vibrant social program, including a welcome reception, a Glühwein gathering, a conference banquet, and a closing ceremony with awards. These events fostered informal exchange, strengthened international collaboration, and contributed to the open and collegial atmosphere that characterizes VCIP.
Best paper award: “AlignGS: Aligning Geometry and Semantics for Robust Indoor Reconstruction from Sparse Views”, Yijie Gao, Houqiang Zhong, Tianchi Zhu, Li Song, Zhengxue Cheng, Qiang Hu (Shanghai Jiao Tong University)
Rising Star: Heming Sun (Yokohama National University), “Traditional and Learned Image and Video Coding: From Algorithms to Implementations”
A successful event for Klagenfurt and the department/university
Hosting VCIP 2025 marked an important milestone for the Department of Information Technology (ITEC) at the University of Klagenfurt, reinforcing its international visibility in the fields of visual computing, multimedia systems, and artificial intelligence. By bringing together experts from academia and industry and opening selected sessions to the wider university community, the conference created valuable opportunities for interdisciplinary exchange and long-term collaboration.
VCIP 2025 concluded with a strong sense of momentum, underscoring the importance of responsible, transparent, and sustainable approaches to visual communication in an AI-driven world. The discussions and connections formed in Klagenfurt will continue to shape research and innovation in the field well beyond the conference itself.
Following a successful edition in Klagenfurt, VCIP 2026 will take place in Singapore from December 13–16, 2026, focusing on “Visual Communications and Image Processing at the Frontiers of Generative and Perceptual AI” (https://vcip-2026.org/).
Posted inATHENA, News|Comments Off on Visual Communication in the Age of AI: VCIP 2025 Highlights from Klagenfurt