Leonardo Peroni (IMDEA Networks Institute and UC3M), Sergey Gorinsky (IMDEA Networks Institute), Farzad Tashtarian (AAU, Austria), and Christian Timmerer (AAU, Austria).
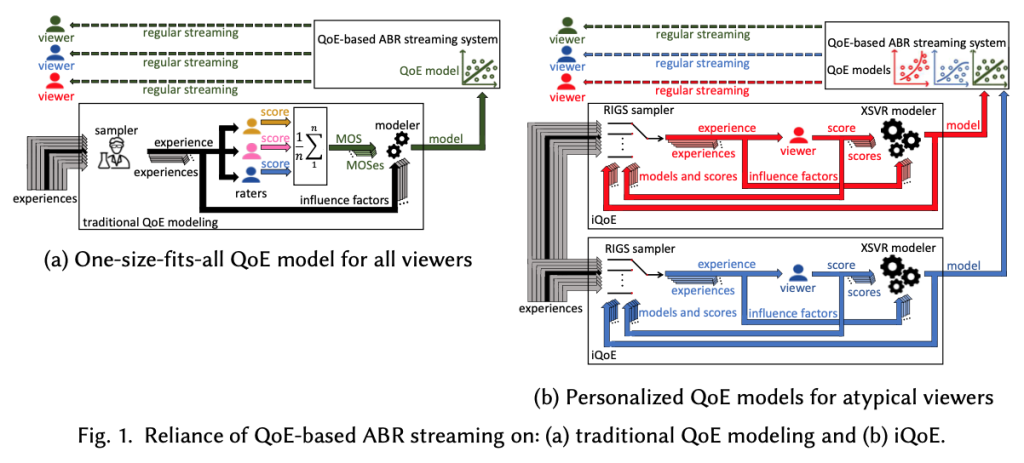
Abstract: Quality of Experience (QoE) and QoE models are of an increasing importance to networked systems. The traditional QoE modeling for video streaming applications builds a one-size-fits-all QoE model that underserves atypical viewers who perceive QoE differently. To address the problem of atypical viewers, this paper proposes iQoE (individualized QoE), a method that employs explicit, expressible, and actionable feedback from a viewer to construct a personalized QoE model for this viewer. The iterative iQoE design exercises active learning and combines a novel sampler with a modeler. The chief emphasis of our paper is on making iQoE sample-efficient and accurate.
By leveraging the Microworkers crowdsourcing platform, we conduct studies with 120 subjects who provide 14,400 individual scores. According to the subjective studies, a session of about 22 minutes empowers a viewer to construct a personalized QoE model that, compared to the best of the 10 baseline models, delivers the average accuracy improvement of at least 42% for all viewers and at least 85% for the atypical viewers. The large-scale simulations based on a new technique of synthetic profiling expand the evaluation scope by exploring iQoE design choices, parameter sensitivity, and generalizability.
Posted inATHENA|Comments Off on Empowerment of Atypical Viewers via Low-Effort Personalized Modeling of Video Streaming Quality
Minh Nguyen (Alpen-Adria-Universität Klagenfurt, Austria), Shivi Vats (Alpen-Adria-Universität Klagenfurt, Austria), Sam Van Damme (Ghent University – imec and KU Leuven, Belgium), Jeroen van der Hooft (Ghent University – imec, Belgium), Maria Torres Vega (Ghent University – imec and KU Leuven, Belgium), Tim Wauters (Ghent University – imec, Belgium), Filip De Turck (Ghent University – imec, Belgium), Christian Timmerer (Alpen-Adria-Universität Klagenfurt, Austria), Hermann Hellwagner (Alpen-Adria-Universität Klagenfurt, Austria)
Abstract: Point cloud streaming has recently attracted research attention as it has the potential to provide six degrees of freedom movement, which is essential for truly immersive media. The transmission of point clouds requires high-bandwidth connections, and adaptive streaming is a promising solution to cope with fluctuating bandwidth conditions. Thus, understanding the impact of different factors in adaptive streaming on the Quality of Experience (QoE) becomes fundamental. Point clouds have been evaluated in Virtual Reality (VR), where viewers are completely immersed in a virtual environment. Augmented Reality (AR) is a novel technology and has recently become popular, yet quality evaluations of point clouds in AR environments are still limited to static images.
In this paper, we perform a subjective study of four impact factors on the QoE of point cloud video sequences in AR conditions, including encoding parameters (quantization parameters, QPs), quality switches, viewing distance, and content characteristics. The experimental results show that these factors significantly impact the QoE. The QoE decreases if the sequence is encoded at high QPs and/or switches to lower quality and/or is viewed at a shorter distance, and vice versa. Additionally, the results indicate that the end user is not able to distinguish the quality differences between two quality levels at a specific (high) viewing distance. An intermediate-quality point cloud encoded at geometry QP (G-QP) 24 and texture QP (T-QP) 32 and viewed at 2.5 m can have a QoE (i.e., score 6.5 out of 10) comparable to a high-quality point cloud encoded at 16 and 22 for G-QP and T-QP, respectively, and viewed at a distance of 5 m. Regarding content characteristics, objects with lower contrast can yield better quality scores. Participants’ responses reveal that the visual quality of point clouds has not yet reached an immersion level as desired. The average QoE of the highest visual quality is less than 8 out of 10. There is also a good correlation between objective metrics (e.g., color Peak Signal-to-Noise Ratio (PSNR) and geometry PSNR) and the QoE score. Especially the Pearson correlation coefficients of color PSNR is 0.84. Finally, we found that machine learning models are able to accurately predict the QoE of point clouds in AR environments.
Index Terms:Point Clouds, Quality of Experience, Subjective Tests, Augmented Reality
Posted inSPIRIT|Comments Off on IEEE Access: Characterization of the Quality of Experience and Immersion of Point Cloud Videos in Augmented Reality through a Subjective Study
Congratulations to Dr. Ekrem Çetinkaya for successfully defending his dissertation on “Video Coding Enhancements for HTTP Adaptive Streaming using Machine Learning” at Universität Klagenfurt in the context of the Christian Doppler Laboratory ATHENA.
Abstract
Video is evolving into a crucial tool as daily lives are increasingly centered around visual communication. The demand for better video content is constantly rising, from entertainment to business meetings. The delivery of video content to users is of utmost significance. HTTP adaptive streaming, in which the video content adjusts to the changing network circumstances, has become the de-facto method for delivering internet video.
As video technology continues to advance, it presents a number of challenges, one of which is the large amount of data required to describe a video accurately. To address this issue, it is necessary to have a powerful video encoding tool. Historically, these efforts have relied on hand-crafted tools and heuristics. However, with the recent advances in machine learning, there has been increasing exploration into using these techniques to enhance video coding performance.
This thesis proposes eight contributions that enhance video coding performance for HTTP adaptive streaming using machine learning. These contributions are presented in four categories:
Fast Multi-Rate Encoding with Machine Learning: This category consists of two contributions that target the need for encoding multiple representations of the same video for HTTP adaptive streaming. FaME-ML tackles the multi-rate encoding problem using convolutional neural networks to guide encoding decisions, while FaRes-ML extends the solution for multi-resolution scenarios. Evaluations showed FaME-ML could reduce parallel encoding time by 41% and FaRes-ML could reduce overall encoding time by 46% while preserving the visual quality.
Enhancing Visual Quality on Mobile Devices: The second category consists of three contributions targeting the need for the improved visual quality of videos on mobile devices. The limited hardware of mobile devices makes them a challenging environment to execute complex machine learning models. SR-ABR explores the integration of the super-resolution approach into the adaptive bitrate selection algorithm. SR-ABR can save up to 43% bandwidth. LiDeR is addressing the computational complexity of super-resolution networks by proposing an alternative that considers the limitations of mobile devices by design. LiDeR can increase execution speed up to 428% compared to state-of-the-art networks while managing to preserve the visual quality. MoViDNN is proposed to enable straightforward evaluation of machine learning-based solutions for improving visual quality on mobile devices.
Light-Field Image Coding with Super-Resolution: Emerging media formats provide a more immersive experience with the cost of increased data size. The third category proposes a single contribution to tackle the huge data size of light field images by utilizing super-resolution. LFC-SASR can reduce data size by 54% while preserving the visual quality.
Blind Visual Quality Assessment Using Vision Transformers: The final category consists of a single contribution that is proposed to tackle the blind visual quality assessment problem for videos. BQ-ViT utilizes recently proposed vision transformer architecture. It can predict the visual quality of a video with a high correlation (0.895 PCC) by using only the encoded frames.
The thesis is available for download here. Slides and video are available as follows:
Congratulations to Dr. Jesús Aguilar Armijo for successfully defending his dissertation on “Multi-access Edge Computing for Adaptive Video Streaming” at Universität Klagenfurt in the context of the Christian Doppler Laboratory ATHENA.
Abstract
Over the last recent years, video streaming traffic has become the dominating service over mobile networks. The two main reasons for the growth of video streaming traffic are the improved capabilities of mobile devices and the emergence of HTTP Adaptive Streaming (HAS). Hence, there is a demand for new technologies to cope with the increasing traffic load while improving clients’ Quality of Experience (QoE). The network plays a crucial role in the video streaming process. One of the key technologies on the network side is Multi-access Edge Computing (MEC), which has several key characteristics: computing power, storage, proximity to the clients and access to network and player metrics. Thus, it is possible to deploy mechanisms at the MEC node that assist video streaming.
This thesis investigates how MEC capabilities can be leveraged to support video streaming delivery, specifically to improve the QoE, reduce latency or increase storage and bandwidth savings. This dissertation proposes four contributions:
Adaptive video streaming and edge computing simulator: A simulator named ANGELA, HTTP Adaptive Streaming and Edge Computing Simulator, was designed to test mechanisms running at the edge node that support video streaming. ANGELA overcomes some issues with state-of-the-art simulators by offering: (i) access to radio and player metrics at the MEC node, (ii) different configurations of multimedia content (e.g., bitrate ladder or video popularity distribution), (iii) support for Adaptive Bitrate (ABR) algorithms at different locations of the network (e.g., server- based, client-based and network-based) and (iv) a wide variety of evaluation metrics. ANGELA uses real 4G/5G network traces to simulate the radio layer, which offers realistic results without simulating the complex processes of the radio layer. Testing a simple MEC mechanism scenario showed a simulation time decrease of 99.76% in ANGELA compared to the simulation using the state-of-the-art simulator ns-3.
Dynamic segment repackaging at the edge: Adaptive video streaming supports different media delivery formats such as HTTP Live Streaming (HLS) [11], Dynamic Adaptive Streaming over HTTP (MPEG-DASH), Microsoft Smooth Streaming (MSS) and HTTP Dynamic Streaming (HDS). This contribution proposes using the Common Media Application Format (CMAF) in the network’s backhaul, performing a repackaging to the clients’ requested delivery format at the MEC node. The main advantages of this approach are bandwidth savings at the network’s backhaul and reduced storage costs at the server and edge side. According to our measurements, the proposed model will also reduce delivery latency if the edge has more than 1.64 times the compute power per segment than the origin server, which is expected due to lower load.
Edge-assisted adaptation schemes: The radio network and player metrics infor- mation available at the MEC node is leveraged to perform better adaptation decisions. Two edge-assisted adaptation schemes are proposed: EADAS, which improves ABR decisions on the fly to increase clients’ QoE and fairness, and ECAS-ML, which moves the whole ABR algorithm logic to the edge and manages the tradeoff among bitrate, segment switches and stalls to enhance QoE. To accomplish that, ECAS-ML utilizes machine learning techniques to analyze the radio network throughput and predict the algorithm parameters that provide the highest QoE. Our evaluation shows that EADAS enhances the performance of ABR algorithms, increasing the QoE by 4.6%, 23.5%, and 24.4% and the fairness by 11%, 3.4%, and 5.8% when using a buffer-based, a throughput-based, and a hybrid ABR algorithm, respectively. Moreover, ECAS-ML shows a QoE increase of 13.8%, 20.85%, 20.07% and 19.29% against a buffer-based, throughput-based, hybrid-based and edge-based ABR algorithm, respectively.
Segment prefetching and caching at the edge: Segment prefetching is a technique that consists of transmitting future video segments to a location closer to the client before they are requested. Hence, the segments are served with reduced latency. The MEC node is an ideal location for performing segment prefetching and caching due to its proximity to the client, its access to radio and player metrics and its storage and computing capabilities. Several segment prefetching policies that use different types and amounts of resources and are based on different techniques, such as a Markov prediction model, machine learning, transrating (i.e., reducing segment bitrate/quality) or super-resolution, are proposed and evaluated. Moreover, the influence on segment prefetching of the caching policy, the bitrate ladder and the chosen ABR algorithm is studied. Results show that the segment prefetching based on machine learning increases the average bitrate by ≈46% while reducing the average number of stalls by ≈20% only increasing the extra bandwidth consumption by ≈6% regarding the baseline simulation with no segment prefetching. Other prefetching policies offer a different combination of performance enhancement and resource usage that can adapt to the service provider’s needs.
Each of these contributions focuses on a different aspect of content delivery for video streaming but can be used jointly to improve video streaming services using MEC capabilities.
EADAS and ECAS-ML can improve the quality adaptation decisions and enable segment prefetching compatibility without the throughput miscalculation issues of client- based ABR algorithms. Moreover, the dynamic repackaging mechanism can be used jointly with segment prefetching and edge-based adaptation schemes to increase bandwidth savings in the backhaul, which reduces the negative impact of some segment prefetching policies.
Congratulations to Dr. Alireza Erfanian for successfully defending his dissertation on “Optimizing QoE and Latency of Video Streaming using Edge Computing and In-Network Intelligence” at Universität Klagenfurt in the context of the Christian Doppler Laboratory ATHENA.
Abstract:
Nowadays, HTTP Adaptive Streaming (HAS) has become the de-facto standard for delivering video over the Internet. More users have started generating and delivering high-quality live streams (usually 4K resolution) through popular online streaming platforms, resulting in a rise in live streaming traffic. Typically, the video contents are generated by streamers and watched by many audiences, geographically distributed in various locations far away from the streamers. The resource limitation in the network (e.g., bandwidth) is a challenging issue for network and video providers to meet the users’ requested quality. This dissertation leverages edge computing capabilities and in-network intelligence to design, implement, and evaluate approaches to optimize Quality of Experience (QoE) and end-to-end (E2E) latency of live HAS. In addition, improving transcoding performance and optimizing the cost of running live HAS services and the network’s backhaul utilization are considered. Motivated by the mentioned issue, the dissertation proposes five contributions in two classes: optimizing resource utilization and light-weight transcoding.
Optimizing resource utilization: This class consists of two contributions, ORAVA and OSCAR. They leverage in-network intelligence paradigms, i.e., edge computing, Network Function Virtualization (NFV), and Software Defined Networking (SDN) to introduce two types of Virtual Network Functions (VNFs): Virtual Reverse Proxy
(VRP) and Virtual Transcoder Functions (VTFs). At the network’s edge, VRPs are responsible for collecting clients’ requests and sending them to an SDN controller. The SDN controller then creates a multicast tree from the origin server to the optimal set of VTFs, delivering only the highest requested bitrate to elevate the efficiency of resource allocation. The selected VTFs transcode the received segment to the requested bitrate and transmit it to the corresponding VRPs. The problem of determining multicast tree(s) and selecting VTFs has been formulated as a Mixed- Integer Linear Programming (MILP) optimization problem, aiming to minimize the streaming cost and resource utilization while considering delay constraints.
ORAVA: It presents a cost-aware approach to provide Advanced Video Coding (AVC)-based real-time video streaming services in the network. It transmits
the generated bitrates from VTFs to corresponding VRPs in a unicast manner.
OSCAR: It extends ORAVA by introducing a new SDN-based live video streaming approach. Instead of unicast transmission, it streams requested bitrates from VTFs to VRPs in a multicast manner, resulting in lower bandwidth consumption. It is also able to use VTFs with different types of virtual machine instances (i.e., CPU or memory resources) to reduce the total service cost.
According to evaluation results, ORAVA and OSCAR save up to 65% bandwidth compared to state-of-the-art approaches; furthermore, they reduce the number of generated OpenFlow (OF) commands by up to 78% and 82%, respectively.
Light-weight transcoding: This class consists of three contributions, named LwTE, CD-LwTE, and LwTE-Live. Employing edge computing and NFV, they introduce a
novel transcoding approach that significantly saves transcoding time and cost.
LwTE: It introduces a novel Light-weight Transcoding approach at the Edge in the context of HAS. During the encoding process of a video segment at the origin side, computationally intense search processes are going on. It stores the optimal results of these search processes as metadata for each video bitrate and reuses them at the edge server to reduce the required time and computational resources for transcoding. It applies a store policy on popular segments/bitrates to cache them at the edge, and a transcode policy on unpopular ones that stores the highest bitrate plus corresponding metadata (of very small size).
CD-LwTE: This contribution extends the investigation on LwTE by proposing Cost- and Delay-aware Light-weight Transcoding at the Edge. As an extension, it introduces resource constraints at the edge and considers a new policy (i.e.,
fetch policy) for serving requests at the edge. In the same direction, it also adds serving delay to the objective of selecting an appropriate policy for each segment/bitrate, aiming to minimize the total cost and serving delay.
LwTE-Live: It investigates the cost efficiency of LwTE in the context of live HAS. It utilizes the LwTE approach to save bandwidth in the backhaul network, which may become a bottleneck in live video streaming.
The evaluation results show that LwTE does the transcoding processes at least 80% faster than the conventional transcoding method. By adding new features in the metadata, CD-LwTE reduces the transcoding time by up to 97%. Moreover, it decreases the streaming costs, including storage, computation, and bandwidth costs, by up to 75%, and reduces delay by up to 48% compared to state-of-the- art approaches.
The thesis is available for download here. Slides and video are available as follows:
Congratulations to Dr. Minh Nguyen for successfully defending his dissertation on “Policy-driven Dynamic HTTP Adaptive Streaming Player Environment” at Universität Klagenfurt in the context of the Christian Doppler Laboratory ATHENA.
Abstract
In the last decades, video streaming has been developing significantly. Among cur- rent technologies, HTTP Adaptive Streaming (HAS) is considered the de-facto approach in multimedia transmission over the internet. In HAS, the video is split into temporal segments with the same duration (e.g., 4s), each of which is then encoded into different quality versions and stored at servers. The end user sends requests to the server to retrieve segments with specific quality versions determined by an Adaptive Bitrate (ABR) algorithm for the purpose of adapting the throughput fluctuation. Though the majority of HAS-based media services function well even under throughput restrictions and variations, there are still significant challenges for multimedia systems, especially the tradeoff among the increasing content complexity, various time-related requirements, and Quality of Experience (QoE). Content complexity encompasses the increased demands for data, such as high-resolution videos and high frame rates, as well as novel content formats, such as virtual reality (VR) and augmented reality (AR). Time-related requirements include – but are not limited to – start-up delay and end-to-end latency. QoE can be defined as the level of satisfaction or frustration experienced by the user of an application or service. Optimizing for one aspect usually negatively impacts at least one of the other two aspects. This thesis tackles critical open research questions in the context of HAS that significantly impact the QoE at the client side. The main contributions of this thesis are four-fold:
This thesis demonstrates that HTTP/3’s features can be utilized to consider- ably enhance the QoE of the end user by improving the video quality. In a streaming session, the end user would have to download low-quality segments, which impair the QoE, due to the throughput fluctuation. We propose Days of Future Past Plus (DoFP+) approach that leverages HTTP/3’s features to upgrade low-quality segments while downloading others. The experimental results reveal a boost in QoE by as much as 33%. In addition, DoFP+ saves an average of 16% of the downloaded data for all test videos. The findings indicate that the sequential download of segments is more advantageous for re- transmissions compared to concurrent downloads, and upgrading lower-quality segments first will result in a more remarkable improvement in QoE.
This thesis proposes a weighted sum model, namely WISH, to provide a high QoE of the video and allow end users to express their preferences among different parameters, including data usage, stall events, and video quality. WISH takes into account three distinct cost elements, namely throughput cost, buffer cost, and quality cost, for each quality version and integrates them into a weighted sum as the overall cost. The results of the experiments indicate that WISH enhances the QoE by up to 17.6% while at the same time reducing data usage by 36.4% in comparison to state-of-the-art approaches. It also offers a dynamic adaptation to meet the demands of end users.
To improve segment qualities on high-end mobile devices, this thesis introduces an ABR scheme called WISH-SR that integrates a lightweight Convolutional Neural Network (CNN) to enhance low-resolution/low-quality videos at the client side. WISH-SR extends WISH by utilizing CNN-based Super Resolution (SR) models deployed in mobile devices to improve video quality while remarkably reducing the volume of data transmitted. WISH-SR has the capacity to reduce up to 43% of the total downloaded data and enhance the visual quality compared to WISH.
Finally, this thesis presents an approach to determine Common Media Client Data (CMCD) parameters from the client and process them at the server for the purpose of generating a suitable bitrate ladder for each client. The bitrate ladder is created based on clients’ device types and network conditions. Our approach is able to reduce the downloaded data while improving the QoE as much as 2.6 times.
Lingfeng Qu (SWJTU, China), Hongjie He (SWJTU, China), Hadi Amirpour (AAU, Austria), Mohammad Ghanbari (University of Essex, UK) , and Christian Timmerer (AAU, Austria)
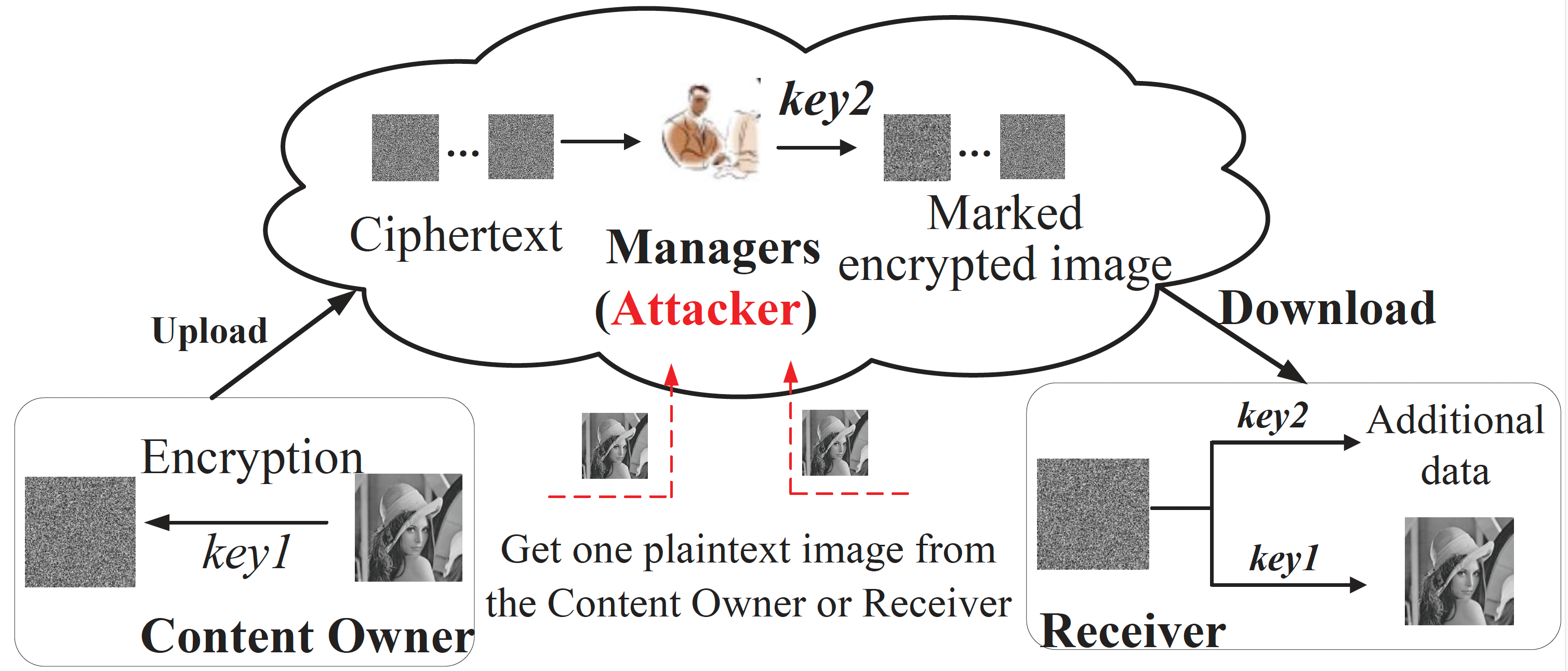
Abstract: In this paper, we propose a novel attack model called the Got Plaintext Attack (GPA), where the attacker only requires one plaintext and the ciphertext image set stored in the cloud to attack the content of the ciphertext image. Using this model, we examine the security of the Improved Redundant Space Transfer (IRST) encryption method. To this end, we define an ordered characteristic matrix based on the properties of the three keys used in IRST. By comparing the histogram distance of the ordered characteristic matrix, we are able to obtain a plain-ciphertext pair. Furthermore, by leveraging the invariant properties of the ordered characteristic matrix of image blocks in the plain-ciphertext pair, we estimate the block permutation Π2 and the bit-plane permutation sequence Π1. Our experiments show that the accuracy of estimating Π2 is higher than 70% for block sizes of 3×3 pixels or larger. Despite a 40% accuracy in estimating Π1, the content information of the ciphertext image can still be exposed.
Posted inATHENA|Comments Off on Cryptanalysis of a Reversible Data Hiding Scheme in Encrypted Images by Improved Redundant Space Transfer