Cross-Modal Scene Semantic Alignment for Image Complexity Assessment
British Machine Vision Conference (BMVC) 2025
November, 2025
Sheffield, UK
[PDF]
Yuqing Luo, YIXIAO LI, Jiang Liu, Jun Fu, Hadi Amirpour, Guanghui Yue, Baoquan Zhao, Padraig Corcoran, Hantao Liu, Wei Zhou
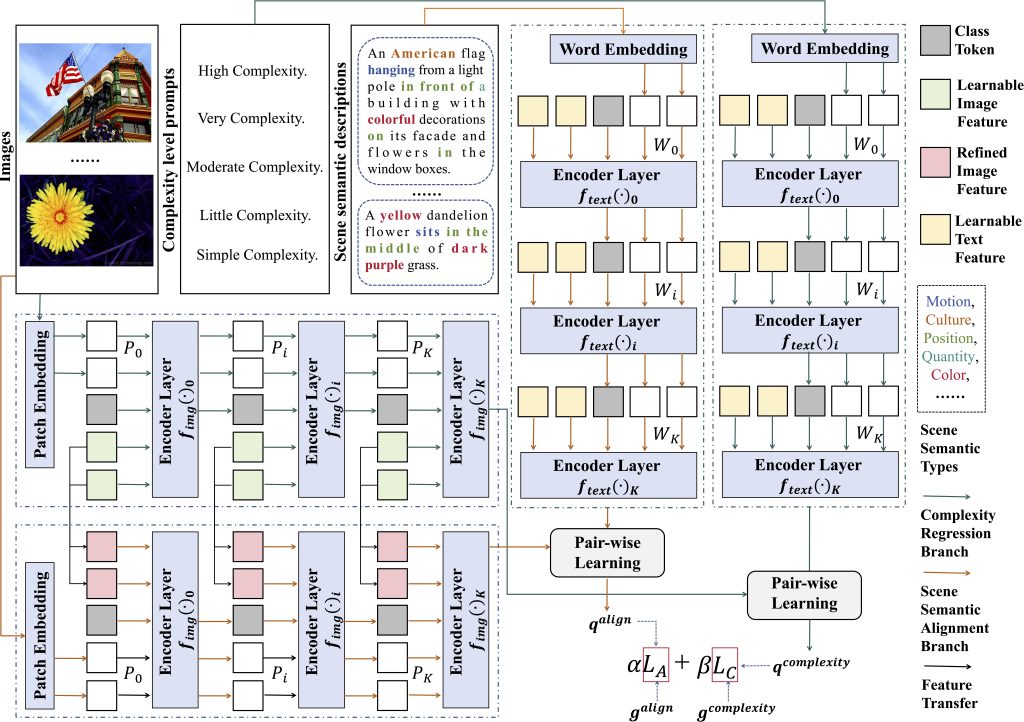
Abstract: Image complexity assessment (ICA) is a challenging task in perceptual evaluation due to the subjective nature of human perception and the inherent semantic diversity in real-world images. Existing ICA methods predominantly rely on hand-crafted or shallow convolutional neural network-based features of a single visual modality, which are insufficient to fully capture the perceived representations closely related to image complexity. Recently, cross-modal scene semantic information has been shown to play a crucial role in various computer vision tasks, particularly those involving perceptual understanding. However, the exploration of cross-modal scene semantic information in the context of ICA remains unaddressed. Therefore, in this paper, we propose a novel ICA method called Cross-Modal Scene Semantic Alignment (CM-SSA), which leverages scene semantic alignment from a cross-modal perspective to enhance ICA performance, enabling complexity predictions to be more consistent with subjective human perception. Specifically, the proposed CM-SSA consists of a complexity regression branch and a scene semantic alignment branch. The complexity regression branch estimates image complexity levels under the guidance of the scene semantic alignment branch, while the scene semantic alignment branch is used to align images with corresponding text prompts that convey rich scene semantic information by pair-wise learning. Extensive experiments on several ICA datasets demonstrate that the proposed CM-SSA significantly outperforms state-of-the-art approaches.