Neural Representations for Scalable Video Coding
IEEE International Conference on Multimedia & Expo (ICME) 2025
June 30 – July 4, 2025
Nantes, France
[PDF]
Yiying Wei (AAU, Austria), Hadi Amirpour (AAU, Austria), and Christian Timmerer (AAU, Austria)
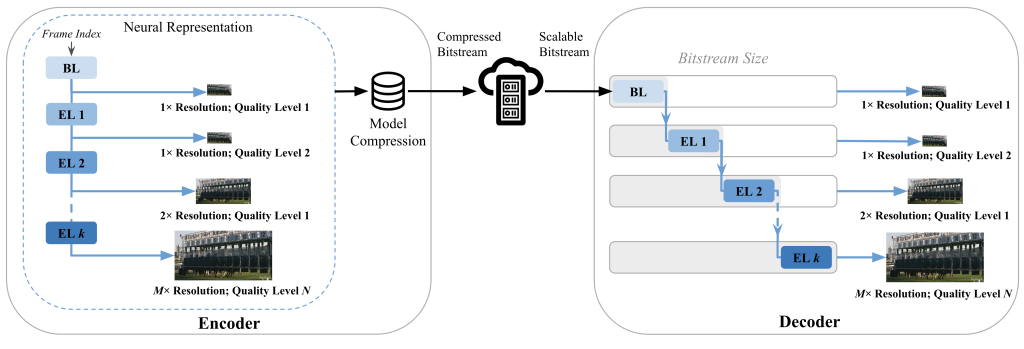
Abstract: Scalable video coding encodes a video stream into multiple layers so that it can be decoded at different levels of quality/resolution, depending on the device’s capabilities or the available network bandwidth. Recent advances in implicit neural representation (INR)-based video codecs have shown competitive compression performance to both traditional and other learning-based methods. In INR approaches, a neural network is trained to overfit a video sequence, and its parameters are compressed to create a compact representation of the video content. While they achieve promising results, existing INR-based codecs require training separate networks for each resolution/quality of a video, making them challenging for scalable compression. In this paper, we propose Neural representations for Scalable Video Coding (NSVC) that encodes multi-resolution/-quality videos into a single neural network comprising multiple layers. The base layer (BL) of the neural network encodes video streams with the lowest resolution/quality. Enhancement layers (ELs) encode additional information that can be used to reconstruct a higher resolution/quality video during decoding using the BL as a starting point. This multi-layered structure allows the scalable bitstream to be truncated to adapt to the client’s bandwidth conditions or computational decoding requirements. Experimental results show that NSVC outperforms AVC’s Scalable Video Coding (SVC) extension and surpasses HEVC’s scalable extension (SHVC) in terms of VMAF. Additionally, NSVC achieves comparable decoding speeds at high resolutions/qualities.