IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
[PDF]
Hadi Amirpour (AAU, Klagenfurt, Austria), Klaus Schoeffmann (AAU, Klagenfurt, Austria), Mohammad Ghanbari (University of Essex, UK), Christian Timmerer (AAU, Klagenfurt, Austria)
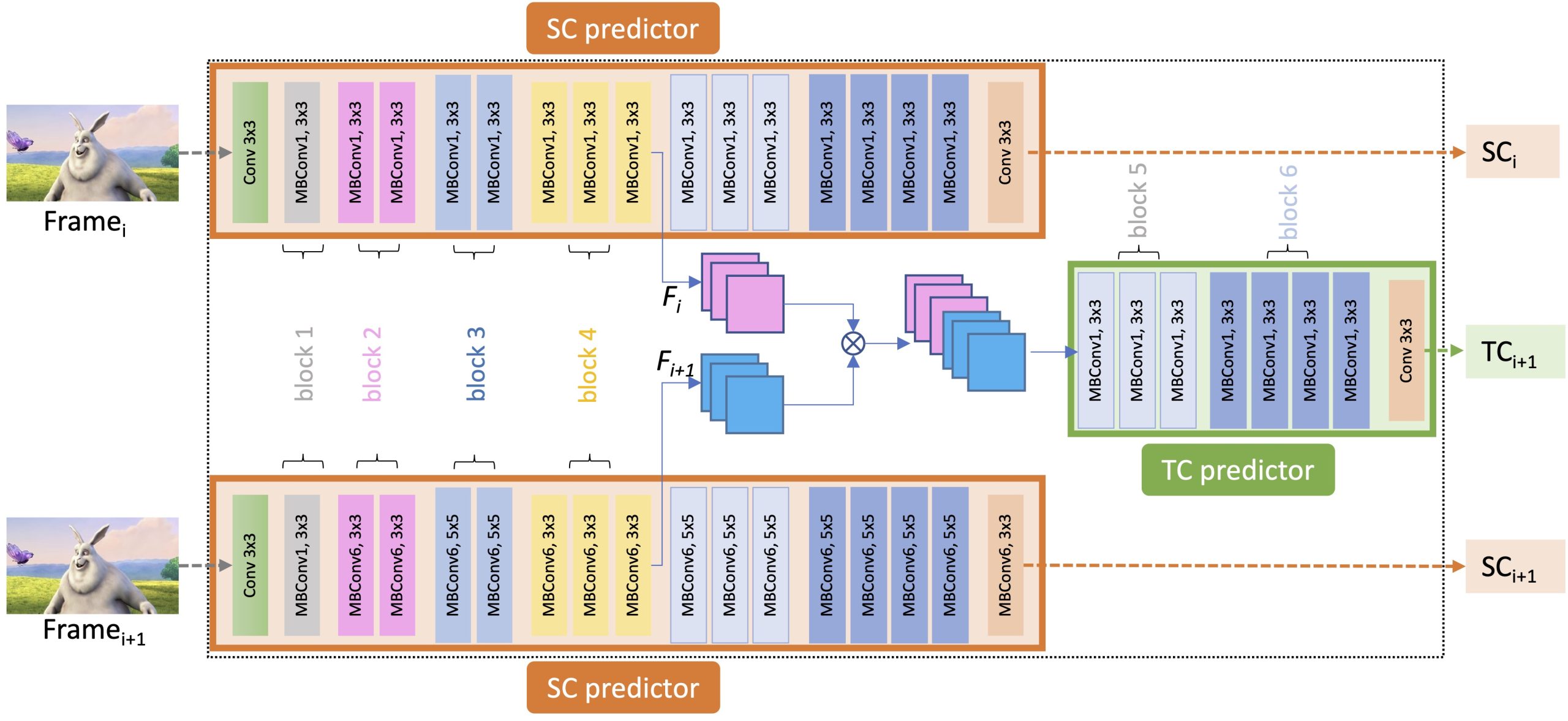
Abstract: Video streaming and its applications are growing rapidly, making video optimization a primary target for content providers looking to enhance their services. Enhancing the quality of videos requires the adjustment of different encoding parameters such as bitrate, resolution, and frame rate. To avoid brute force approaches for predicting optimal encoding parameters, video complexity features are typically extracted and utilized. To predict optimal encoding parameters effectively, content providers traditionally use unsupervised feature extraction methods, such as ITU-T’s Spatial Information ( SI ) and Temporal Information ( TI ) to represent the spatial and temporal complexity of video sequences. Recently, Video Complexity Analyzer (VCA) was introduced to extract DCT-based features to represent the complexity of a video sequence (or parts thereof). These unsupervised features, however, cannot accurately predict video encoding parameters. To address this issue, this paper introduces a novel supervised feature extraction method named DeepVCA, which extracts the spatial and temporal complexity of video sequences using deep neural networks. In this approach, the encoding bits required to encode each frame in intra-mode and inter-mode are used as labels for spatial and temporal complexity, respectively. Initially, we benchmark various deep neural network structures to predict spatial complexity. We then leverage the similarity of features used to predict the spatial complexity of the current frame and its previous frame to rapidly predict temporal complexity. This approach is particularly useful as the temporal complexity may depend not only on the differences between two consecutive frames but also on their spatial complexity. Our proposed approach demonstrates significant improvement over unsupervised methods, especially for temporal complexity. As an example application, we verify the effectiveness of these features in predicting the encoding bitrate and encoding time of video sequences, which are crucial tasks in video streaming. The source code and dataset are available at https://github.com/cd-athena/ DeepVCA.