IEEE Internet of Things Journal (IEEE IoT)
[PDF]
Hongjie He (Southwest Jiaotong University, China), Yuan Yuan (Southwest Jiaotong University, China), Hadi Amirpour (AAU, Klagenfurt, Austria), Lingfeng Qu (Southwest Jiaotong University, China), Christian Timmerer (AAU, Klagenfurt, Austria), Fan Chen (Southwest Jiaotong University, China)
Abstract: With the development of Internet of Things (IoT) and cloud services, many images generated from IoT devices are stored in the cloud, calling for efficient data encryption methods. To balance the security and usability, the thumbnail preserving encryption (TPE) has emerged. However, existing JPEG image-based TPE (JPEG-TPE) schemes face challenges in achieving low file extension, lossless decryption and better privacy protect of detailed information. To solve these challenges, we propose a novel JPEG-TPE scheme.
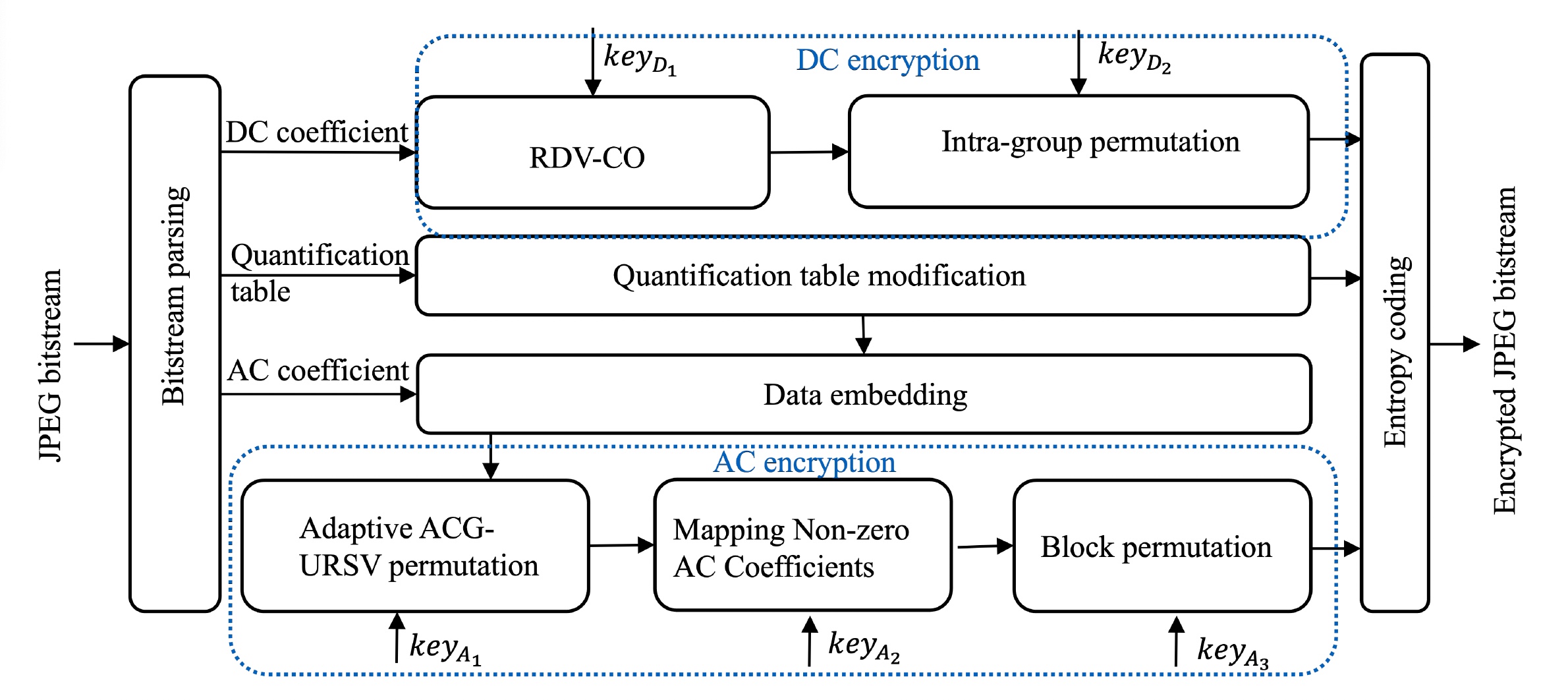
Firstly, to achieve a smaller file size expansion and preserve the thumbnail, we reallocate the values, maintaining the sum for the DC difference instead of the DC coefficient. To ensure that the coefficients do not overflow, the valid range of reallocated difference is constrained not only by the sum but also by the neighborhood difference.
Secondly, to preserve file size of AC encryption while improve the security of detailed information, the AC coefficient groups with undivided RSV are permuted adaptively.
Besides, the intra TPE block swapping of DC difference, quantization table modification,
non-zero AC coefficients mapping, and block permutation are used to further encrypt the image. The experimental results show that the proposed JPEG-TPE scheme achieves lossless decryption, reducing the file size expansion of encrypted images from 15.41% to 0.64% compared to the state-of-the-art scheme. Additionally, it is observed that the proposed method can effectively resist against various attacks, including the deep-learning based super-resolution attack.